
Introduction
Engineering is the subject of using science knowledge to design and build something. I chose the sub-subject of Engineering which is “Water Resource” as my research object. This paper would focus on the groundwater Research, which collecting the data to build the model to analyze the groundwater resource. It is tough for students to write this kind of research paper. The reason is that we are not familiar with the professional terms, sentence structures, text format, etc. of this “water Resource” paper. Therefore, the purpose of this paper is to explore and analyze language usage in groundwater resource papers with the help of the Corpus. This paper can help students to get a summary of the language usage in the engineering academic writing related to Water Resources Research so that we can be more confident when we write the academic paper.
Research question
This paper will set out to answer five questions: (1) what are top-10 most frequently used words in my selected journal articles and how are they used in terms of collocation? (2) Whether the word “temperature” and the word “weather” will appear frequently? (3) What are the top 3 most frequently used words after “water” or “groundwater”, and is there any differences between different journals? (4) What are the percentages of AWL, GSL first 1000 words, and second 1000 words in my corpus? (5) What are the top 5 frequently used academic words in my corpus?
Expectation
The following are expected results regarding each question before the analysis of the corpus was conducted: (1) To the first question, I expect that the word “model” or “modeling” will make a significant number of appearances throughout the corpus. The reason is that the center of the engineering study is to build models to analyze problems. Besides the word “model”, I also expect the word “data” will appear frequently. This is due to the Engineering paper will be based on research and use plenty of data to show the results. For the collocation, I expect the word “SS” will commonly follow the word “model” since “SS model” is “State Space model”, which is the mathematical representation of a physical system. It’s a very vital model structure in Engineering study. In addition, some words I think will follow the word “data” is the word “set” and “collection”. (2) For the second question, I expect word “temperature” and “weather” to appear regularly. The reason is that I think they are the main factors affect the groundwater considerably. (3) For the third question, I expect word “depletion”, “recharge”, “discharge” will emerge after the groundwater, since they are all the commonly used professional terms to describe the groundwater’s situation. (4) For the fourth question, I expect that around 8% of the paper will use academic language which indicate their level of professionalism. (5) For the final question, I think the top 5 frequently used academic words in my selected journals is word “data” , “research”, “global” , “area”,” scenarios”.
Methods
Research Procedure
In order to conduct my research, I will use the “AntConc” to analyze all my expectations. This software is specifically designed to analyze a corpus of texts by finding common phrases, words, and other important aspects. First, I will convert all files into “.txt” files to be usable. Second, comparing 10 articles. Five of them are coming from the 2019-2022, other five are coming from the 1965-1970. These articles are all from the “Water Research”, which is a journal publishing the water related journals from 1960. This “Water Research “journal was published from the “AGU”, a science journal publisher.
Corpus Description
In total, the corpus contained 88074 word-tokens and 7098 unique word types. Since all the articles are download in PDF, and they all have broadly equations and model graphs, there will be some formatting errors when convert these files to TXT. It is very hard to remove some unnecessary words, so this may cause some, but not major, variability in the results. Since the articles will be analyzed as an entire corpus, and rarely individually, the articles will be listed here so that all credit can be acknowledged.
| Article number | Article title | Article author |
| 1 | “A distributed heat pulse sensor network for thermo-hydraulic monitoring of the soil subsurface” | Abesser, C., Ciocca, F., Findlay, J., Hannah, D., Blaen, P., Chalari, A |
| 2 | “Regional strategies for the accelerating global problem of groundwater depletion” | Aeschbach-Hertig, W., & Gleeson, T |
| 3 | “Crop evapotranspiration: Guidelines for computing crop water requirements” | Allen, R. G., Pereira, L. S., Raes, D., & Smith, M. |
| 4 | “Vulnerabilidad a la contaminación del acuífero Potrero-Caimital, Nicoya Guanacaste. Servicio Nacional de Aguas Subterraneas” | Agudelo, C. |
| 5 | “Seawater intrusion in complex geological environments” | Abarca, E. |
| 6 | “Competition for shrinking window of low salinity groundwater” | Grant Ferguson, Jennifer C McIntosh, Debra Perrone, Scott Jasechko |
| 7 | “Stable Isotopes of Water and Nitrate for the Identification of Groundwater Flowpaths” | Hyejung Jung, Dong-Chan Koh, Yun S. Kim, Sung-Wook Jeen, Jeonghoon Lee. |
| 8 | “Depletion percentage and nonlinear transmissivity as design criteria for groundwater-level observation networks” | Jesse T. Korus, Heidi J. Hensen |
| 9 | “A Two‐Stage Bayesian Data‐Driven Method to Improve Model Prediction” | Xiaozhuo Sun, Xiankui Zeng, Jichun Wu, Dong Wang |
| 10 | “Urban Geochemistry” | David T. Long, W. Berry Lyons. |
Tools
The following procedures and tools in AntConc were used to answer each question: To answer the first question, I used the “Word List” and open my selected article to show the top 10 frequently used academic words in my selected articles. For the second question, I used the “Clusters/N-Gram” and typed in my keywords to see the frequent words before or after my keywords. For the third question, I still used the “Clusters/N-Gram” to find common phrases used in my corpus. For the last question: downloading the Academic Word List, GWL first and second 1000 words lists into the Word List tool via the “Tool Preferences” setting first, making sure to also select the “choose from words below” option. Then, these settings were applied and the total number of word tokens that matched this list was then divided by the total word tokens for the document to get the percentage of the document utilizing academic language.
Findings and Discussion
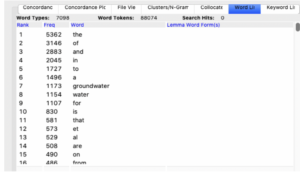
I found the top 10 frequently used words are almost the article, the preposition, or the conjunction: for example, “a”,” the”,” and” etc. Additionally, words “groundwater” and “water” are the seventh and eighth most frequent words. “groundwater” showed up 1173 times and “water” showed up 1154 times. Since my corpus was focusing on the “Water Research”, these two words had not surprised me greatly. After that, using “Clusters/N-Gram” and put the keywords “model” inside, setting sorted by right side. I found word “SS” appeared 56 times followed by the word “model”. Then, changed the setting to sort by left side. Input word “data”. Word phrase “data set” and “data collection” appeared 20 times and 24 times respectively. (2) For to the second question, changed the cluster size from 1 to 1, then typed word “weather” and “temperature” into the “Clusters/N-Gram” to figure out their frequency. It showed that they all showed up 24 times in these 10 journals. Moreover, put in the word “weather” and “temperature” in “Concordance Plot”. I found the word “weather” and “temperature” have been used
frequently in articles in 2021. The word “weather” only one occurrence in articles in 1974. the “temperature”, it shows up 8 times total in articles from 1960 to 1975.

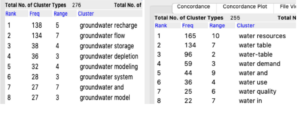
“Clusters/N-Gram” and set sorting by right side, cluster size from 2 to 2, then put in word “water” and “groundwater” separately. It showed that “groundwater recharge”, “groundwater flow”, “groundwater storage” “Water resources” and “water table” “water demand” were used most frequently.
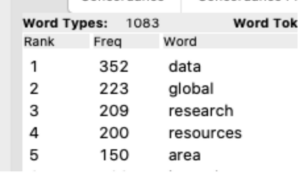
(4) For the fourth question, there were 9950 word tokens and 1083 word types of academic words used in my selected journals. After calculation, the percent of AWL in my corpus is 11.3 percent. For the first 1000 GSL, there are 62629-word tokens and 2635 word types in my corpus. Therefore, the percentage is 71 percent. For the second 1000 GSL, there are 67355 word tokens and 3172 word types. The percentage is 76.5 percent. (5) For the last question, the top 5 frequently used AWL word is “data”, “global”, “research”, “resources” and “area”.
Conclusion
Overall, most of my expectations were confirmed: (1) For the first expectation, I expected the top 10 frequently words to include the word “model” or “data”. They all appeared over 300 times, although they were not in the top-10 frequent words lit, they still showed up repeatedly. It confirms the rigor of these papers, which were based on experimental studies and data analysis. Besides, word “water” or “groundwater” frequency were top 7 and 8 in my corpus, which had not surprised me a lot because these journals were focused on the same topic—Water Research. (2) For the second expectation, words “weather” and “temperature” appeared rarely in the past 60 years, but they appeared much more times in recent articles. This could because science and technology are getting better to understand some of the factors that affect groundwater. (3) For my third expectation, the word “groundwater depletion” is a very technical term to describe the lack of groundwater which also appeared frequently in articles. There were also some terms were commonly used in water resources research, like “groundwater recharge”, “groundwater discharge”, which all appeared very frequently in my corpus. (4) For the fourth expectation, the percentage of the AWL words and GSL words in my selected journals all fit my expectation. (5) For my final expectation. the top 5 frequently used AWL words are “data”, “research”, “resources” and “global” and “area”, which fit my assumption. The reason is that these words are all the fundamental words used to write the research paper.
Evaluating the results of this study, the implications of its findings are not groundbreaking or far-reaching, but it did show some key details to keep in mind while conducting and reading water resources analysis: for example, it is vital to understand the specific terms related to the water resources field before you try to study it, it is important to understand what it talked about. Although there are a number of limitations, here are the two most important: first, the scope of the study was not far-reaching. The corpus only included 10 journals. To gain a solid understanding of water resource language, further research should expand the range of journals up to thousands of reports—included in the corpus. A second important limitation of this corpus was lots of graph and equation are included in the corpus, and also have some errors when convert PDF to text. For the improvement is to delete all the graphs and equation as well as modify the file format to eliminate some errors. Overall, most of my expectation was fitted, and I’m really satisfied with the thing I found.