
What did I have to build to collect my data? Well, it started with a lot of Googling and help from fellow students and computer science professors at Lafayette College who know a bit more about programming than I do.
First, I needed to figure out how to build a web scraper to collect all the data from Supreme Court cases from caselaw.findlaw.com, like this one. The image below is a screenshot of what the source code to Citizens United‘s webpage.
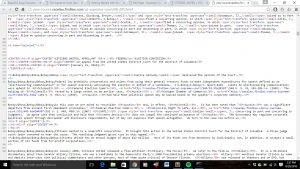
You can see the different tags on the HTML code. If you look closely, you can see that there is a marking called “opinion1”. That’s where Justice Anthony Kennedy’s majority opinion begins. That tag is standardized for most of the cases on this webpage and, for most Supreme Court cases past 2009, the URL for the website is determined by the case’s docket number. There’s also another collection of tags that mark when the majority opinion ends.
But how was that information useful to me? Good question. It took me a bit of time to figure that out, too. Although I had some coding experience before, I had never built a web scraper. And I had only coded in Java. But Python seemed like the easiest language to code web scrapers in, so I downloaded it on my computer and started learning it by doing lots of Googling, using Codecademy, Learn Python the Hard Way, and Stack Overflow. All of these are great resources for anyone trying to learn to code. Plus, Learn Python the Hard Way also taught me command line, which I needed to learn for this project, too.
The best Python library for accessing HTML tags was Beautiful Soup. There are instructions on the website on how to download it–it’s very easy, and most of the documentation is fairly intuitive. A screenshot of the page is below.
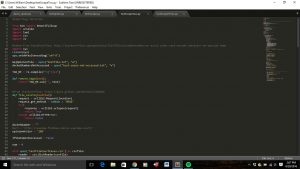
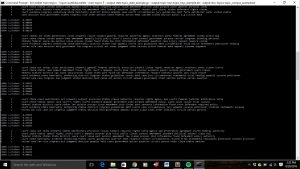
I used other libraries, too, so I could clean the HTML code to produce a text file without the HTML tags. I also created a file that kept track of the cases’ docket numbers and names that couldn’t be accessed by my code, so I could manually copy them into the text fine later. All of the docket number were taken from a CSV file I got from Harold Spaeth’s Supreme Court Database. A picture of my code is below, written using the text editor Sublime. You can check it out here.
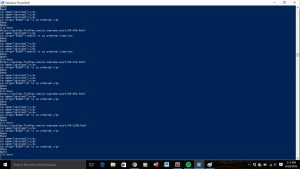
I then ran my code in Windows PowerShell. If you look closely, you can see the website its accessing, and the print-out statements on the tags its accessing at the beginning and end of the opinions.
Once I had my data, I needed a way to perform topic-modeling analysis on it. MALLET seemed like the best program I found. It’s complicated to use, but The Programming Historian has a great tutorial on how to do it. Using Command Line, I plugged in the data set I wanted to topic modeling, put in the amount of topics I wanted, and got two sets of data back: the collections of words that make up the “topics” and the percentage of how much of the each text file they compose. These data sets were used to produce the graphs you see in the “Results” portion of this website.
Other variations of this process were used to create a code that limited the data collection to an issue area, different numbers of topics and different data sets.