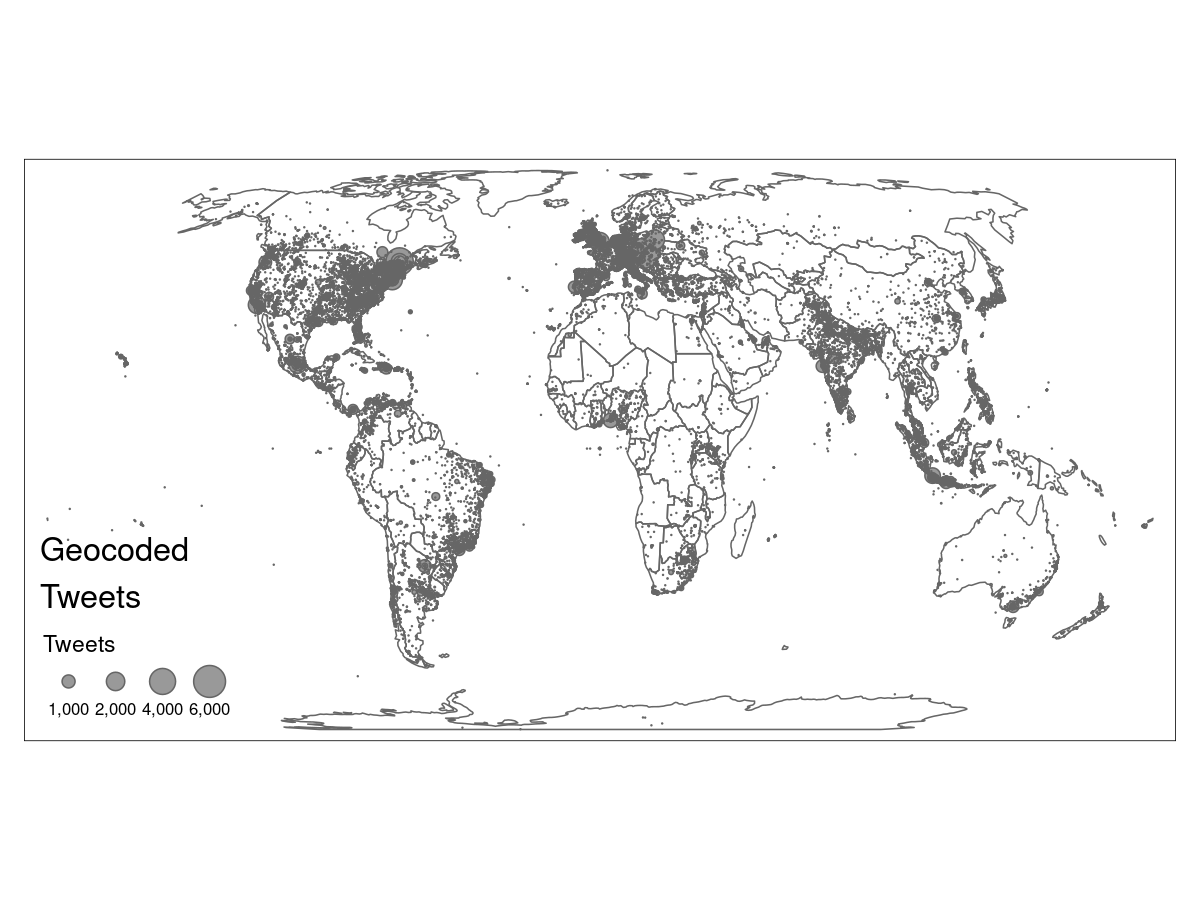
The objective of this work is to explore popular discourse about the COVID-19 pandemic and policies implemented to manage it. Using Natural Language Processing, Text Mining, and Network Analysis to analyze a corpus of tweets that relate to the COVID-19 pandemic, we identify common responses to the pandemic and how these responses differ across time. Moreover, insights as to how information and misinformation were transmitted via Twitter, starting at the early stages of this pandemic, are presented. Finally, this work introduces a dataset of tweets collected from all over the world, in multiple languages, dating back to January 22nd, when the total cases of reported COVID-19 were below 600 worldwide. The insights presented in this work could help inform decision-makers in the face of future pandemics, and the dataset introduced can be used to acquire valuable knowledge to help mitigate the COVID-19 pandemic.
Christian Lopez, Malolan Vasu, and Caleb Gallemore (2020) Understanding the perception of COVID-19 policies by mining a multilanguage Twitter dataset. arXiv:cs.SI/2003.10359,2020 https://arxiv.org/abs/2003.10359
The repository contains an ongoing collection of tweets IDs associated with the novel coronavirus COVID-19. The dataset contains Tweets’ ids dating back to January 22th, 2020. The Twitter’s search API was used to gather historical Tweets from multiple continents in multiple languages that contained a given keyword (e.g., coronavirus, virus, covid, ncov19, ncov2019). The dataset is on:
- GitHub : lopezbec/COVID19_Tweets_Dataset
- KaggleCovid19-tweets-dataset
GeoLocated Coronavirus Tweets from 1/22/2020 to 4/24/2020